基本概念
TTS
TTS(Text-to-Speech,文本转语音) 是一种将文本内容转换为自然语音的技术。它可以让计算机“读”出文字,常用于智能助手、有声读物、导航播报、无障碍阅读、客服机器人等应用。
Zero-Shot
零样本语音克隆(Zero-Shot Voice Cloning) 是 TTS(文本转语音)技术中的一种高级能力,指 无需对目标说话人进行专门训练,仅凭一段短音频样本,就能让模型模仿该说话人的声音来生成任意文本的语音。
零样本语音克隆的特点
-
无需额外训练 传统 TTS 想要模仿某人的声音,需要收集大量该人录音并对模型进行微调。 零样本方法只需要 几秒钟的参考音频(5-15 秒) 即可完成声音克隆。
-
实时性强 由于不需要训练,零样本语音克隆可以直接在推理阶段完成声音特征提取与语音生成。
-
多说话人泛化能力 模型在训练时已经接触到大量不同音色的语音数据,学会了“分离音色和内容”,因此能快速适应一个新的声音。
F5-TTS
F5-TTS(全称 A Fairytaler that Fakes Fluent and Faithful Speech with Flow Matching)是 2024 年由 SWivid 团队提出的一款 零样本语音克隆(Zero-Shot Voice Cloning)TTS 模型。它以高自然度、快速合成和中英双语支持而著称,被认为是开源 TTS 模型中音质最接近商用级的方案之一。
F5-TTS 的特点
- 零样本语音克隆(Zero-Shot) 只需一段 5-15 秒的参考音频(ref_audio),就可以模仿目标声音生成任意文本的语音。
不需要对目标说话人进行单独训练。
- 高音质和自然度 采用 Flow Matching 技术,比传统自回归模型(如 Tacotron 2)速度更快、语音更平滑。
基于 HiFi-GAN 声码器,提升音质。
- 多语种支持 官方检查点(checkpoint)支持 中英文,可无缝切换。
对中英混合语音表现优异。
-
高速合成 在消费级显卡上可接近实时生成,RTF(Real Time Factor)低至 0.15,意味着 1 秒语音仅需 0.15 秒生成。
-
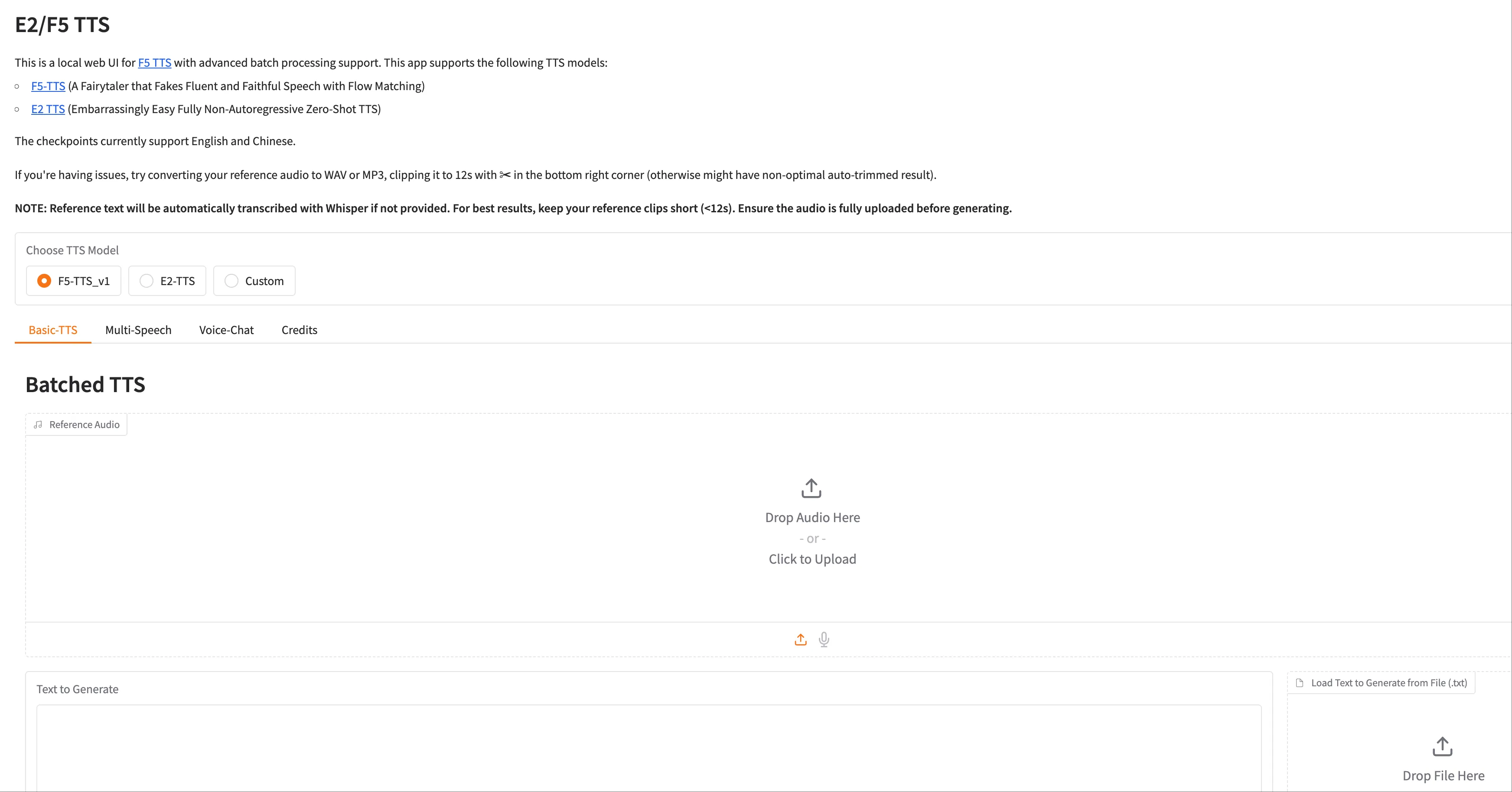
批处理 & Gradio UI 官方提供 Gradio Web UI,可上传多段参考音频,支持多角色对话与批量文本生成。
多种语音类型生成(Multiple Speech-Type Generation)
这是 F5-TTS(或类似高级 TTS 系统)提供的一项功能,用于 在一次生成中切换多种语气、情感或不同角色的声音,从而实现 丰富多样的语音表达。该功能特别适合 有声剧、视频配音、角色对话 等场景。
- 多语气/多情感切换 你可以在同一段输入文本中通过 标签(speech type) 指定不同的语气,例如:
-
{Regular} 普通语气
-
{Angry} 生气
-
{Curious} 好奇
-
{Happy} 开心
-
{Whisper} 低声细语
- 多角色/多声音合成 除了情感切换,还可以通过 多段参考音频(ref_audio) 和 多标签 来模拟不同角色的声音,例如:
{"name": "Speaker1_Happy", "seed": -1, "speed": 1} 你好,今天心情不错。
{"name": "Speaker2_Sad", "seed": -1, "speed": 1} 可我有点伤心。- 批量生成
可以上传一个 .txt 文件,里面包含多行对话,每行都可以带不同的 {SpeechType} 标签。 也可以上传多段参考音频,每段对应一个特定的语气或角色
安装依赖
安装 Python 和虚拟环境
# 建议 Python 3.10 以上
python3 -m venv f5env
source f5env/bin/activate安装 F5-TTS
pip install f5-tts如果需要 Apple Silicon M1/M2 上的加速,先安装对应的 PyTorch 版本:
pip install torch torchaudio --index-url https://download.pytorch.org/whl/cpu启动 Gradio 界面
安装完成后,F5-TTS 内置了一个 Gradio demo:
f5-tts_infer-gradio注意:请保持网络通畅,启动过程会从 Hugging Face下载模型。
运行后,终端会显示
Starting app...
* Running on local URL: http://127.0.0.1:7860用浏览器访问 http://127.0.0.1:7860 就能打开 F5-TTS 的 Web 界面。